What is the Robots.txt File in a Domain?

One of the biggest mistakes for new website owners is not looking into their robots.txt file. So what is it anyway, and why so important? We have your answers.
If you own a website and care about your site’s SEO health, you should make yourself very familiar with the robots.txt file on your domain. Believe it or not, that are a disturbingly high number of people who quickly launch a domain, install a quick WordPress website, and never bother doing anything with their robots.txt file.
This is dangerous. A poorly configured robots.txt file can destroy your site’s SEO health and damage any chances you may have for growing your traffic.
What is the Robots.txt File?
The Robots.txt file is aptly named because it’s essentially a file that lists directives for the web robots (like search engine robots) on how and what they can crawl on your website. This has been a web standard followed by websites since 1994, and all major web crawlers adhere to the standard.
The file is stored in text format (with a .txt extension) on the root folder of your website. You can view any website’s robot.txt file just by typing the domain followed by /robots.txt. If you try this with groovyPost, you’ll see an example of a well-structured robot.txt file.
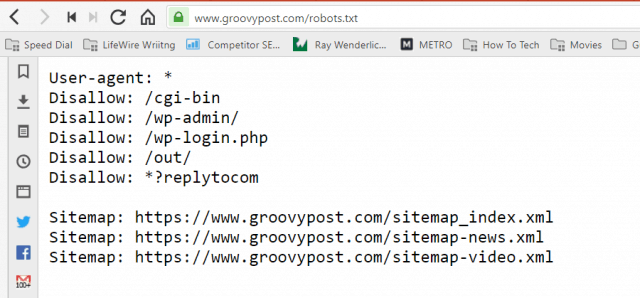
The file is simple but effective. This example file doesn’t differentiate between robots. The commands are issued to all robots by using the User-agent: * directive. This means that all commands that follow it apply to all robots that visit the site to crawl it.
Specifying Web Crawlers
You could also specify specific rules for specific web crawlers. For example, you might allow Googlebot (Google’s web crawler) to crawl all articles on your site. Still, you may want to disallow the Russian web crawler Yandex Bot from crawling articles on your site that have disparaging information about Russia.
Hundreds of web crawlers scour the internet for information about websites, but the 10 most common you should be concerned about are listed here.
- Googlebot: Google search engine
- Bingbot: Microsoft’s Bing search engine
- Slurp: Yahoo search engine
- DuckDuckBot: DuckDuckGo search engine
- Baiduspider: Chinese Baidu search engine
- YandexBot: Russian Yandex search engine
- Exabot: French Exalead search engine
- Facebot: Facebook’s crawling bot
- ia_archiver: Alexa’s web ranking crawler
- MJ12bot: Large link indexing database
Taking the example scenario above, if you wanted to allow Googlebot to index everything on your site but wanted to block Yandex from indexing your Russian-based article content, you’d add the following lines to your robots.txt file.
User-agent: googlebot
Disallow: Disallow: /wp-admin/
Disallow: /wp-login.php
User-agent: yandexbot
Disallow: Disallow: /wp-admin/
Disallow: /wp-login.php
Disallow: /russia/
As you can see, the first section only blocks Google from crawling your WordPress login page and administrative pages. The second section stops Yandex from the same, but also from the entire area of your site where you’ve published articles with anti-Russia content.
This is a simple example of how you can use the Disallow command to control specific web crawlers that visit your website.
Other Robots.txt Commands
Disallow isn’t the only command you have access to in your robots.txt file. You can also use any other commands that will direct how a robot can crawl your site.
- Disallow: Tells the user-agent to avoid crawling specific URLs or entire sections of your site.
- Allow: Allows you to fine-tune specific pages or subfolders on your site, even though you might have disallowed a parent folder. For example, you can disallow: /about/, but then allow: /about/ryan/.
- Crawl-delay: This tells the crawler to wait xx number of seconds before starting to crawl the site’s content.
- Sitemap: Provide search engines (Google, Ask, Bing, and Yahoo) the location of your XML sitemaps.
Keep in mind that bots will only listen to the commands you’ve provided when you specify the bot’s name.
People make a common mistake by disallowing areas like /wp-admin/ from all bots, but then specify a Googlebot section and only disallowing other regions (like /about/).
Since bots only follow the commands you specify in their section, you need to restate all of those other commands you’ve selected for all bots (using the * user-agent).
- Disallow: The command used to tell a user agent not to crawl a particular URL. Only one “Disallow:” line is allowed for each URL.
- Allow (Only applicable for Googlebot): The command to tell Googlebot it can access a page or subfolder even though its parent page or subfolder may be disallowed.
- Crawl-delay: How many seconds a crawler should wait before loading and crawling page content. Note that Googlebot does not acknowledge this command, but the crawl rate can be set in Google Search Console.
- Sitemap: Used to call out the location of an XML sitemap(s) associated with this URL. Note this command is only supported by Google, Ask, Bing, and Yahoo.
Remember that robots.txt is meant to help legitimate bots (like search engine bots) crawl your site more effectively.
There are many nefarious crawlers out there that are crawling your site to do things like scrape email addresses or steal your content. Don’t bother if you want to try and use your robots.txt file to block those crawlers from crawling anything on your site. The creators of those crawlers typically ignore anything you’ve put in your robots.txt file.
Why Disallow Anything?
Getting Google’s search engine to crawl as much quality content on your website as possible is a primary concern for most website owners.
However, Google only expends a limited crawl budget and crawl rate on individual sites. The crawl rate is how many requests per second Googlebot will make to your site during the crawling event.
More critical is the crawl budget, which is how many total requests Googlebot will make to crawl your site in one session. Google “spends” its crawl budget by focusing on areas of your site that are very popular or have changed recently.
You aren’t blind to this information. If you visit Google Webmaster Tools, you can see how the crawler is handling your site.

As you can see, the crawler keeps its activity on your site pretty constant every day. It doesn’t crawl all sites, but only those it considers to be the most important.
Why leave it up to Googlebot to decide what’s essential on your site when you can use your robots.txt file to tell it what the most critical pages are? This will prevent Googlebot from wasting time on low-value pages on your site.
Optimizing Your Crawl Budget
Google Webmaster Tools also lets you check whether Googlebot is reading your robots.txt file fine and whether there are any errors.
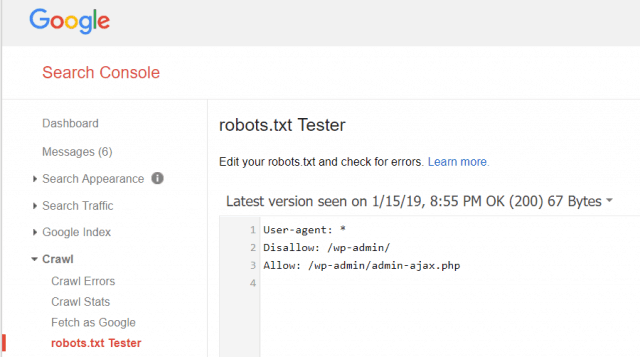
This helps you verify that you’ve structured your robots.txt file correctly.
What pages should you disallow from Googlebot? It’s good for your site SEO to disallow the following categories of pages.
- Duplicate pages (like printer-friendly pages)
- Thank you pages following form-based orders
- Order or information query forms
- Contact pages
- Login pages
- Lead magnet “sales” pages
Don’t Ignore Your Robots.txt File
The biggest mistake new website owners make is never even looking at their robots.txt file. The worst situation could be that the robots.txt file is blocking your site, or areas of your site, from getting crawled at all.
Make sure to review your robots.txt file and ensure it’s optimized. This way, Google and other essential search engines “see” all of the fabulous things you offer the world with your website.





